Recent advancements in the text-rendering capabilities of image generation models have made the end-to-end creation of graphic design content, such as posters, increasingly feasible. However, existing reward models fall short of accurately assessing design quality, as they primarily focus on global image aesthetics while overlooking the critical dimensions of typography and layout. Furthermore, the scarcity of domain-specific preference data remains a significant bottleneck, limiting the further development of graphic design evaluation and generation.
To bridge this gap, we design an automated pipeline to construct a high-quality dataset of 70k poster preferences by leveraging the consensus of multiple Multi-modal Large Language Models (MLLMs) to simulate human-like judgment. Based on this dataset, we propose PosterReward, a reward model specifically designed for high-precision poster assessment through a cascaded, multi-stage training strategy. We also provide multiple variants of the model to cater to different application scenarios. Finally, we introduce PosterRewardBench and PosterBench to evaluate the performance of existing reward models in poster assessment and the generation capabilities of current text-to-image models in poster creation, respectively.
Image + prompt are first analyzed, then mapped to scalar reward scores via the scoring module.


A lightweight pointwise evaluator that predicts scores directly from image + prompt with minimal latency.
A pairwise judge that compares two candidates and outputs preference decisions with interpretable textual reasoning.
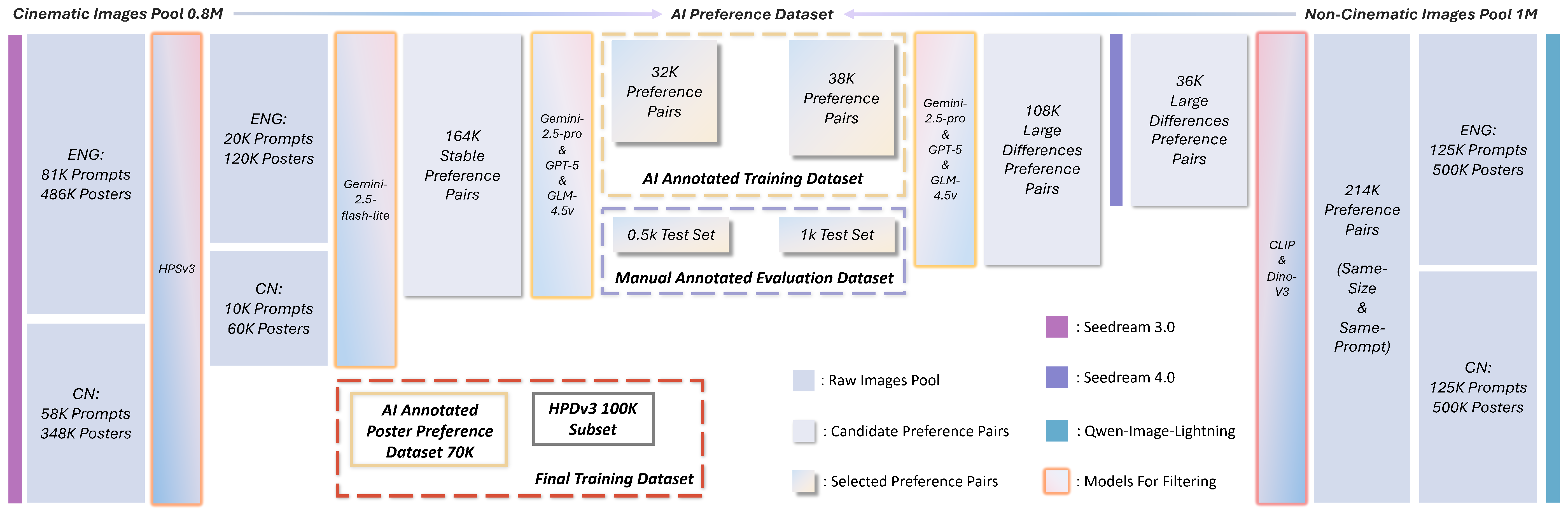
Automated AI-judged preference data pipeline with cascaded filtering, pair generation, and multi-model consensus validation.

Representative chosen-vs-rejected preference pairs, with dimensions such as aesthetics, text readability, layout coherence, and prompt alignment.
We build cinematic and non-cinematic sample pools from multiple generators, then progressively reduce noise using aesthetic scoring, similarity constraints, and stability checks before expensive model voting.
Preference labels are verified by multiple advanced MLLMs under order-swapped pairwise prompting, which suppresses positional bias and retains only stable, high-confidence comparisons.
The final dataset emphasizes typography, layout, and instruction faithfulness, addressing the underrepresentation of graphic design quality signals in general-purpose visual preference datasets.
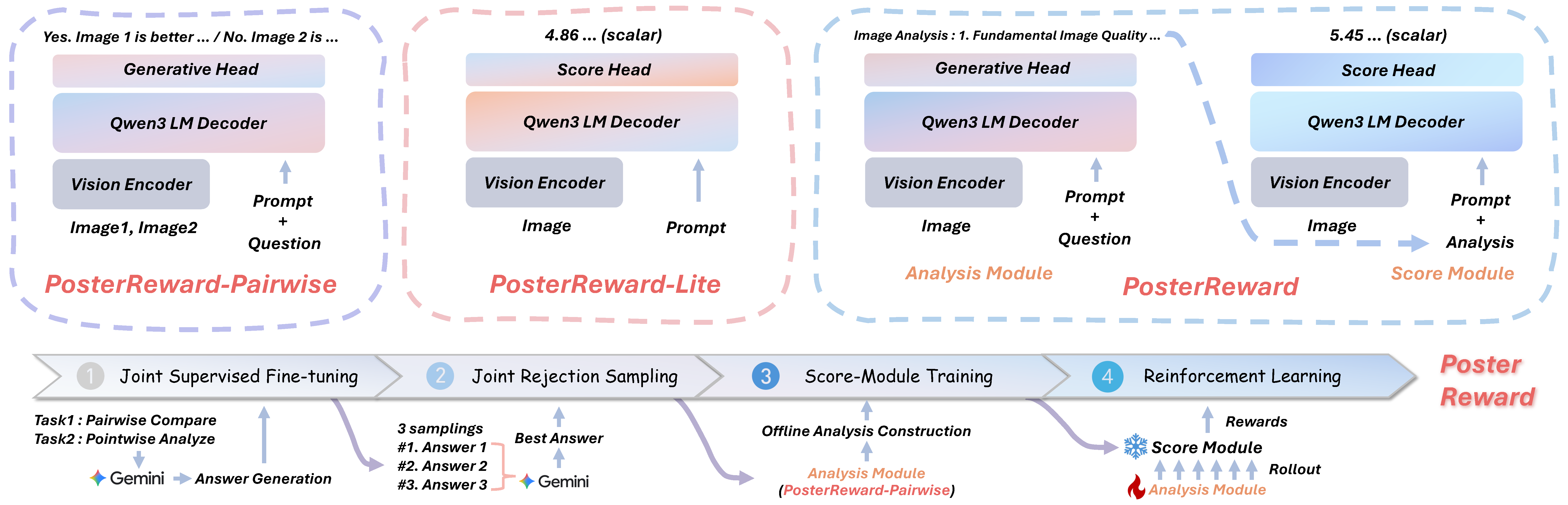
The complete cascaded framework that unifies discriminative and pairwise reward learning through SFT, rejection sampling, score-module optimization, and reinforcement fine-tuning.
Single-image analysis and paired-image comparison are trained together, then refined by rejection sampling to improve answer quality and preference consistency.
The scoring head is optimized on chosen/rejected triplets with Bradley-Terry loss, converting rich analysis into stable scalar reward differences.
A GRPO stage improves analysis outputs while keeping the scorer frozen, making final rewards more robust for downstream post-training.
We evaluate PosterReward against existing reward models on poster assessment tasks, demonstrating superior performance in both pointwise accuracy and pairwise preference prediction.
Performance comparison across various benchmarks. All values represent accuracy (↑). PRB is an abbreviation for PosterRewardBench.
| Model | MMRB2 | HPDv3 | PRB-Basic | PRB-Ad |
|---|---|---|---|---|
| ImageReward | 53.0 | 58.6 | 60.7 | 49.3 |
| PickScore | 57.6 | 65.6 | 66.7 | 44.1 |
| HPSv2 | 55.0 | 65.3 | 70.8 | 43.7 |
| UnifiedReward* | 56.9 | 59.4 | 60.0 | 52.7 |
| HPSv3 | 58.5 | 76.9 | 72.9 | 41.2 |
| PosterReward-Lite | 60.5 | 77.1 | 83.9 | 85.0 |
| PosterReward | 59.6 | 77.8 | 86.7 | 86.0 |
Performance comparison on PosterRewardBench (PRB). "Yes" and "No" refer to the accuracy on samples with positive and negative ground truth labels, respectively.
| Model | PRB-Basic Acc. ↑ | PRB-Ad Acc. ↑ | ||||
|---|---|---|---|---|---|---|
| Yes | No | Avg. | Yes | No | Avg. | |
| UnifiedReward-think | 75.1 | 61.5 | 68.3 | 52.6 | 48.5 | 50.6 |
| Qwen3-VL-Plus | 89.9 | 39.2 | 64.5 | 98.7 | 14.2 | 56.4 |
| Gemini-2.5-Flash | 94.7 | 33.3 | 64.0 | 95.2 | 28.8 | 62.0 |
| Gemini-2.5-Pro | 75.6 | 83.1 | 79.3 | 81.8 | 68.6 | 75.2 |
| GPT-5 | 90.4 | 80.5 | 85.4 | 89.8 | 75.9 | 82.9 |
| PosterReward-Pairwise | 82.0 | 84.0 | 83.0 | 84.1 | 83.6 | 83.8 |
Human evaluation demonstrates the progressive improvement of our cascaded training strategy.
Overall preference comparison across different training stages. Right model win rate increases progressively with each component.
We analyze the contribution of each component in our cascaded training framework.
| Method | Advanced Acc. ↑ | Basic Acc. ↑ | ||||
|---|---|---|---|---|---|---|
| Yes | No | Avg. | Yes | No | Avg. | |
| SFT (Single) | 81.77 | 82.09 | 81.93 | 80.85 | 82.59 | 81.72 |
| SFT (Joint) | 82.09 | 83.32 | 82.71 | 80.08 | 83.75 | 81.92 |
| + RSFT (Single) | 82.67 | 83.24 | 82.96 | 80.66 | 83.56 | 82.11 |
| + RSFT (Joint) | 84.06 | 83.57 | 83.82 | 82.01 | 83.95 | 82.98 |
"Yes" and "No" refer to the ground truth of the response.
| Model / Component | HPDv3 | PRB-Basic | PRB-Ad |
|---|---|---|---|
| PosterReward-Lite | 77.1 | 83.9 | 85.0 |
| + Analysis | 77.5 | 85.7 | 85.8 |
| + Analysis + GRPO | 77.8 | 86.7 | 86.0 |
Cumulative impact of each component on key benchmarks.
Performance comparison of closed-source and open-source image generation models on PosterBench, highlighting both average quality and stability across prompts.
| Model | Mean ↑ | Median ↑ | Std-Avg ↓ | Bo8-Avg ↑ |
|---|---|---|---|---|
| Closed-Source Models | ||||
| Nano-Banana-Pro | 13.36 | 13.47 | 1.91 | 15.77 |
| Seedream-4.5* | 12.03 | 12.09 | 2.08 | 14.57 |
| Nano-Banana[8] | 11.60 | 11.69 | 2.17 | 14.49 |
| Seedream-4.0[37] | 11.46 | 11.44 | 2.06 | 13.93 |
| GPT-Image-1 | 11.16 | 11.38 | 1.75 | 13.43 |
| Seedream-3.0[10] | 5.01 | 5.13 | 3.66 | 9.75 |
| Open-Source Models | ||||
| Qwen-Image-2512[46] | 11.86 | 11.63 | 1.46 | 13.85 |
| Qwen-Image[46] | 7.69 | 7.72 | 2.55 | 11.06 |
| Z-Image-Turbo[2] | 7.65 | 7.31 | 2.18 | 10.47 |
| Flux.2-klein-9B[2] | 7.38 | 7.66 | 3.20 | 11.67 |
| Flux.1-krea-dev[22] | 5.00 | 5.14 | 3.59 | 9.58 |
| Flux.1-dev[20] | 2.55 | 2.42 | 3.85 | 7.81 |
| SD3.5-L[9] | -2.90 | -3.92 | 2.68 | 1.24 |
PosterBench evaluation results. Mean, Median, and Bo8-Avg represent the corresponding scores, while Std-Avg measures stability across prompt groups, where lower is better.
PosterReward provides dense, design-aware scalar feedback over typography, composition, and semantic faithfulness, making it suitable as a reward function in post-training loops for image generation systems.
The pairwise model improves preference reliability and interpretability, while the discriminative scorer supports efficient large-batch optimization, offering a unified path from data curation to policy improvement.
The reward transfers naturally to reinforcement fine-tuning and iterative policy improvement for poster generation, helping models move from generic aesthetics to task-specific design quality.
PosterReward enables effective post-training improvement through GRPO training. Below we show qualitative comparisons between models before and after applying PosterReward-guided optimization.
Visual comparison of Flux.1-dev fine-tuned with various reward models. From left to right, the columns display the outputs of the original Flux.1-dev, followed by models fine-tuned using PosterReward, HPSv3, UnifiedReward and PickScore. The corresponding prompts are enclosed at the bottom.




















Visual comparison of Qwen model fine-tuned with various reward models. From left to right, the columns display the outputs of the original Qwen, followed by models fine-tuned using PosterReward, HPSv3, UnifiedReward and PickScore. The corresponding prompts are enclosed at the bottom.



















